Automatic News Scene Segmentation by Integrating Visual Features and Rules
Organizing video sequences from shot level to scene level is a challenging task, however, without the scene information, it would be very hard to extract the content of the video. In this paper, a visual and rule information integrated strategy is proposed to detect the scene information of the News programs. First, we extract out the video caption and anchor person (AP) shots in the video; Second, the rules among the scene, video caption, AP shots will be used to detect the scenes; Third, the visual features will also be used to analysis the scene information in the region which can not be covered by the rules. And experimental results based on this strategy are provided and analyzed on broadcast News videos.
A scene unit of a News programs just means a semantic independently News item which express a semantic independent event in the video. Most of the other scene detection methods put much emphasis on color, motion and other visual information in the shot. However, in our algorithm, we want to integrate the visual information and rule information of the video to detect the scene unit. After we browse and statistic tens of CCTV News and SHTV News, we found out the common rules among all these News programs:
- The AP shot always act as the separator between scenes, that means, wherever we found out a AP shot in the News, the shot succeed and precede are always belong to different scenes. The AP may make some comment about the last scene, however, it will always give the overview information of the scene succeed.
- In each scene of News programs, there always has at least one video caption to explain the semantic content of the current News item. Comparing with sound and image information, the text will always present a more tidy abstract information, it can also be used to help the people with obstacle in hearing.
- The shots in the same scene are not always similar in visual information, however, since all the shot in one scene are semantic related. These visual features will be helpful to determine the shot number and the boundary of each scene.
With all the common features of the News programs, a visual feature and rules integrated strategy will be presented to detect the scene information of the broadcast News. The strategy can be described as steps below:
- Detect all AP shots and video captions at first.
- If there is only one video caption between each two AP shots, then, group the shots between these two AP shots as one scene, and, take the first AP shot as the first shot of this scene. Such as AP shot 3 in Fig. 1(A).
- In very rare situation, there may have no any video caption between each two AP shots, then, take the shots between this area as one scene. Such as AP shot 2 in Fig. 1(A).
- If there are more than one video captions between two AP shots, such as AP shot 1 in Fig. 1(A), this may be caused by several scene or one scene with several video captions. Visual feature will be used to detect the scene information in this region.
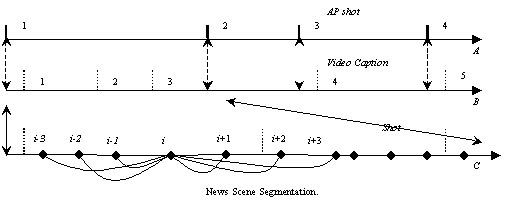
Figure 1 News scene detection by integrating visual features and rules

Fiture 2. Scene architecture in News program

Fiture 3. Generated News scene units
Towards video group, scene detection for video content hierarchy construction
By integrating the low-level features and knowledge information, most semantic units in the video could be detected out efficiently. However, those strategies can only be utilized at the specific domains, to develop a general video semantic unit detection strategy and utilize the detected semantic units to construct video content table will help us in video content management and access.
Video group detection
The shots in one group usually share similar background or have a high correlation in time series. Therefore, to segment the spatially or temporally related video shots into groups, a given shot is compared with the shots that precede and succeed it (no more than 2 shots) to determine the correlation between them, as shown in Figure 4. Assume StSim(Si,Sj) denotes the similarity between shot Si and Sj. Our group detection procedure is stated as below:
Input: Video shots. Output: Video groups
Procedure:
1. Given any shot Si, if CRi is larger than TH2-0.1: a. If R(i) is larger than TH1, claim a new group starts at shot Si.. b. Otherwise, go to step 1 to process other shots.
2. Otherwise: a. If both CRi and CLi are smaller than TH2, claim a new group starts at shot Si. b. Otherwise, go to step 1 to process other shots.
3. Iteratively execute step 1 and 2 until all shots are parsed successfully.
The definitions of CRi, CLi, R(i) are given in below:
CLi =Max{ StSim(Si,Si-1), StSim(Si,Si-2)}; CRi =Max{ StSim(Si,Si+1), StSim(Si,Si+2)}; CLi+1 =Max{ StSim(Si+1,Si-1), StSim(Si+1,Si-2)}; CRi+1 =Max{ StSim(Si+1,Si+2), StSim(Si+1,Si+3)}; R(i)=(CRi+CRi+1)/(CLi+CLi+1).
Since closed caption and speech information is not available in our strategy, the visual features such as color, texture play a more important role in determining the shots in one group. Using the shot grouping strategy above, two kinds of shots are absorbed into a given group (as shown in Figure 5): (1) shots related in temporal series, where similar shots are shown back and forth. Shots in this group are temporally related; (2) shots similar in visual perception, where all shots in the group are similar in visual features. Shots in this group are spatially related.

Figure 4. Video group detection
Group Merging for Scene Detection
Since our shot grouping strategy places more emphasis on the details of the scene, one scene may be grouped into several groups, as shown in Figure 5. However, groups in the same scene usually have higher correlation with each other when compared with other groups in different scenes. Hence, a group merging method is introduced to merge adjacent groups with higher correlation into one scene:
Input: Video groups (Gi, i=1,..,M) Output: Video scenes (SEj, j=1,..,N).
Procedure:
1. Given groups Gi, i=1,..,M, calculate similarities between all neighboring groups (SGi, i=1,..,M-1) with Equation 1., where GpSim(Gi,Gj) denotes the similarity between group Gi and Gj.
SGi=GpSim(Gi, Gi+1) i=1,..,M-1 (1)
2. Use the automatic threshold detection strategy to find the best group, merging threshold (TG) for SGi, I=1,..,M-1, with TG=ATD(SGi).
3. Adjacent groups with similarity larger than TG are merged into a new group. If there are more than 2 sequentially adjacent groups with larger similarity than TG, all are merged into a new group.
4. The reserved and newly generated groups are formed as a video scene. Scenes containing only two shots are eliminated, since they usually convey less semantic information than scenes with more shots.
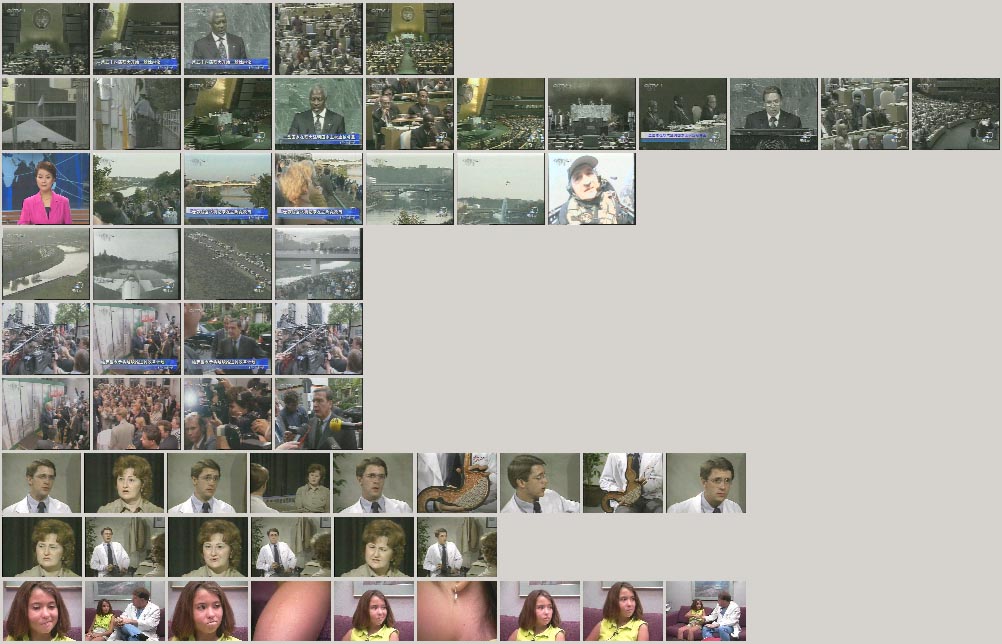
Figure 5. Video group detection results

Fiture 6. Scene detection results by utilizing group merging
Scene clustering
Using the results of group merging, video scene information can been constructed. However, in most situations, many scenes would be shown several times in the video. To cluster those similar scenes into one unit eliminates the redundancy and produces a more concise video content summary. Since the general K-meaning cluster algorithm needed to seed the initial cluster center, and the initial guess of cluster centroids and the order in which feature vectors are classified can affect the clustering result, we introduce a seedless Pairwise Cluster Scheme (PCS) for video scene clustering:
Input: Video scenes (SEj, j=1,..,M) and all member groups (Gi, i=1,..,NG) . Output: Clustered scene structure (SEk, k=1,..,N).
Procedure:
1. Given video groups Gi, i=1,..,NG, we first calculate the similarities between any group Gi and Gj (i=1,..,NG-1; j=1,..,NG-1). The similarity matrix (SMij) for all groups is computing using Eq. (2).
SMij(Gi,Gj)=GpSim(Gi,Gj), i=1,..,NG-1; j=1,..,NG-1 (2)
where GpSim(Gi,Gj) denotes the similarity between Gi and Gj. For any
scene SEj, it either consists of one or several groups. Hence, the similarity
matrix of all scenes (![]() ) can
be derived from the group similarity matrix (SMij) with Eq. (3) i=1,..,M;
j=1,..,M (14)
) can
be derived from the group similarity matrix (SMij) with Eq. (3) i=1,..,M;
j=1,..,M (14)
![]()
2. Find the largest value in matrix , and merge the corresponding scenes into a new scene, and use SelectRepGroup() to find the representative group (scene centroid) for newly generated scene.
3. After we have obtained the desired number of clusters, go to end; if not, go to step 4.
4. Based on the group similarity matrix SMij and the updated centroid
of the newly generated scene, update the scene similarity matrix ![]() with
Eq. (3) directly, then go to step 2.
with
Eq. (3) directly, then go to step 2.
In order to determine the end of the scene clustering at step 3, the number of clusters N needs to be explicitly specified. Our experimental results have shown that for a great deal of interesting videos, if we have M video scenes, then using a clustering algorithm to reduce the number of scenes by 40% produces a relatively good result with respect to eliminating the redundancy and reserving important video scenes. However, a fixed threshold often loses the adaptive ability of the algorithm. Hence, to find an optimal number of clusters, we have employed the cluster validity analysis. The intuitive approach is to find clusters that minimize intra-cluster distance while maximizing the inter-cluster distance.
With the strategies above, a three layer video content hierarchy (group, scene, clustered scene) could be constructed. By integrating video key-frame and shot, a five layer video content hierarchy (key-frame, shot, group, scene, clustered scene) is attained. With this content table, lots of applications or implementations could be executed.
Hierarchical video summarization and content description joint semantic and visual similarity
Video is increasingly the medium of choice for a variety of communication channels, resulting primarily from increasing levels of networked multimedia content. One way to keep our heads above the video waters is to provide summaries of video content in a more tractable format. Some existing approaches use different kinds of features to generate summary, but are mainly limited to locate the low-level feature related important units. Since the semantic information, the content and structure of the video do not correspond to these low-level features directly even with close caption, scene detection, audio signal processing, the drawbacks are: (1) On comparing with unfolding the semantic content and structure among the video, those low-level related units usually only address the details; (2) Any important unit selection strategy based on low-level features would be hard to be applied on general videos.
To provide users with an overview of the video content at various levels of abstraction which is attractive for more efficient database retrieval and browsing, a hierarchical video content description and summarization strategy is presented in this paper, where joint semantic and visual similarity has been developed. In order to describe video content efficiently and accurately, a semi-automatic video annotation strategy is firstly presented which utilize the hierarchical semantic network and relevance feedback to acquire the video content description at various layers. Based on achieved semantic network, a hierarchical group structure is constructed by group merging and clustering. After that, a 4 layers video summary with different granularity is acquired to assist users unfold the video content in a progressive way. Experiments based on real-word videos validate the effectiveness of the proposed approach.
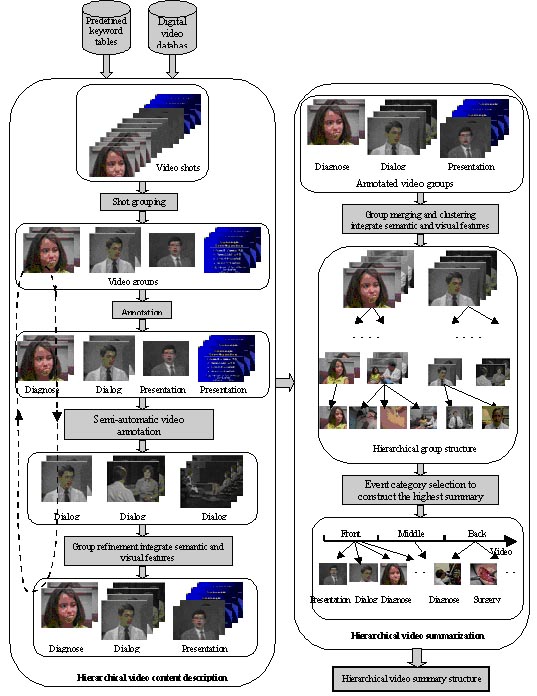
Figure 7. Hierarchical video summarization and content description
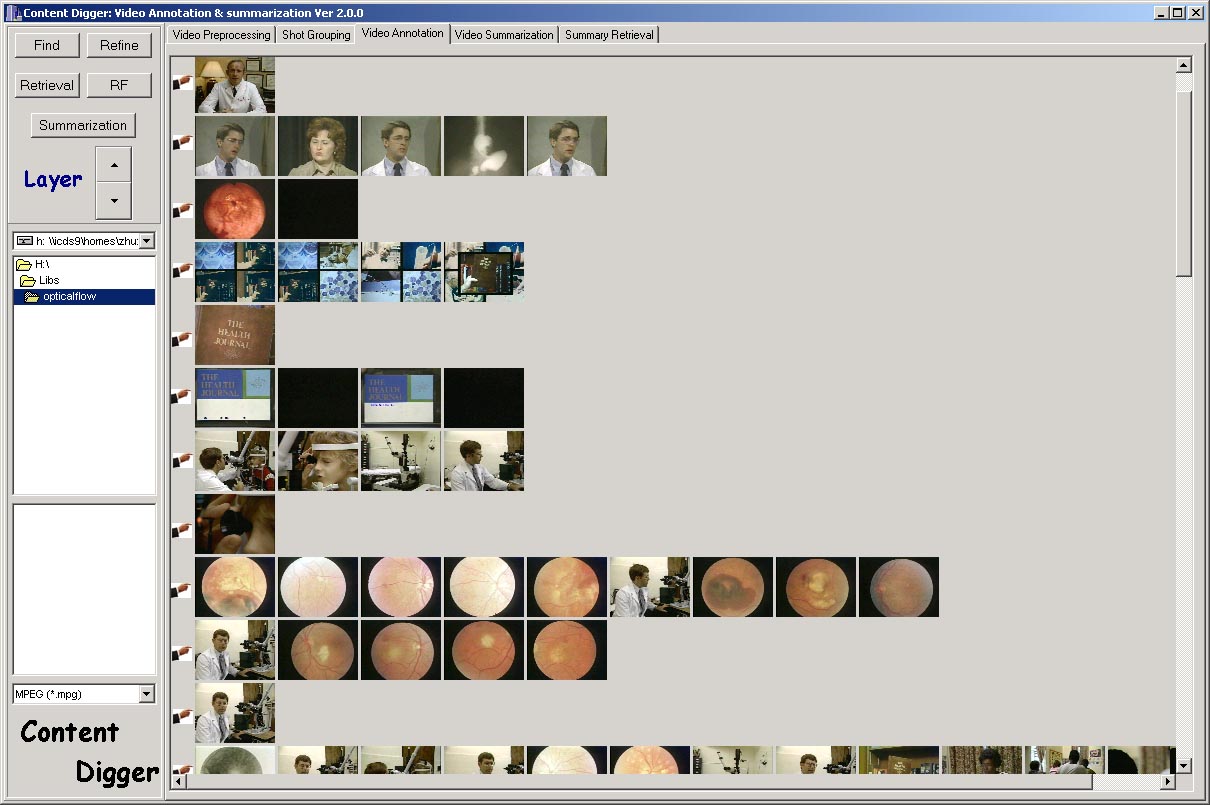
Figure 8. Semi-automatic video content annotation
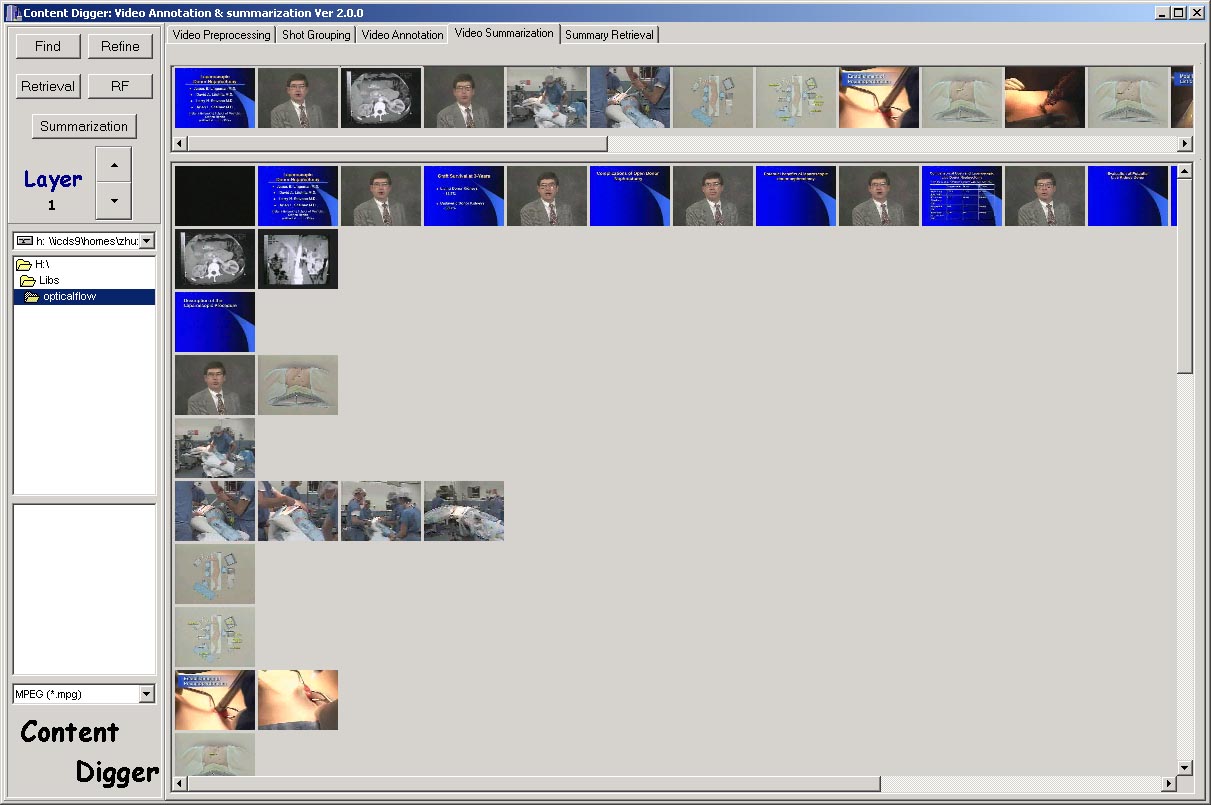
Figure 9. Hierarchical video content summarization